第8回「フェノーム統合データベース」
はじめに
研究開発の材料として用いられる生物系統,集団,組織,細胞,DNAなどの生物遺伝資源をバイオリソースという.個々のバイオリソースはそれぞれのゲノムがもつ特性(遺伝型)に応じて,生物学的な特性(フェノタイプ,表現型)をもっている.一般に,フェノタイプはいわゆる正常である野生型との対比により決まる.つまり,個々のバイオリソースについて固有に決まる性質よりも,複数のバイオリソースのあいだでの比較(組合せ)によりもたらされる"違い"や"同等性"がきわめて重要な意味をもつ.
フェノタイプは生命システムにおけるさまざまな階層において観測される特性であり,環境と相互に作用しあうことにより多様な表現型が生み出される.フェノタイプのもととなるデータは,生命システムのそれぞれの階層において網羅的な分子計測やそのほかの技術により観測される(図1).オミックスとは,それぞれの階層に存在する多数の分子(DNA,RNA,タンパク質,代謝産物)がそれぞれの生物においてどれくらい存在しているかを網羅的に調べる技術である.こうした計測データを多数の生物材料のあいだで比較解析することで,フェノタイプを階層ごと網羅的に調べることができる.
しかし従来は,それぞれの研究グループが自前で準備した生物材料について独自に計測していたため,異なる研究グループによる階層の異なるデータを関連づけることはむずかしく,多階層のデータを統合的に比較解析することはほとんど行われていなかった.これに対し近年では,バイオリソースの基盤,すなわち,それぞれの研究分野で開発されてきた実験用の系統や株をはじめとする実験材料の収集,保存,提供のシステムが整備され生物材料が標準化されたことにより,異なる研究グループが計測したデータであっても生物材料の共通性を足がかりとしてデータを比較解析することが可能となった.バイオリソースセンターが標準化した同一の品質をもつ生物材料が多数の研究者に供給されることにより,ある研究者は転写産物のデータを計測し,ある研究者は代謝産物のデータを計測した場合でも,同じ生物材料に由来するものであればそれらのデータを統合的に比較解析することができるのである.
よって,それぞれのバイオリソースについて蓄積されたさまざまなデータを収集蓄積し体系化して公開することはたいへんに重要である.多くの研究者が同じ生物材料を軸にさまざまな比較解析を行うことが可能となるだけでなく,それぞれの生物材料にデータが蓄積していくことでバイオリソースの価値も高まっていく.たとえば,バイオリソースセンターからある研究者が生物材料を入手し独自に計測したデータにくわえて,ほかの研究者がその生物材料について計測したデータも比較解析に用いることができるからである.このように,バイオリソースを軸として,さまざまな生物において測定された多種類のフェノタイプのデータを多面的に比較することを可能としたデータベースをフェノームデータベースという(図1).もちろん,ひとつの機関だけですべての生物材料のすべての階層のフェノタイプを網羅的に計測することはできない.このため,計測は国際的な分担により行われる傾向にあり,複数の機関が連携することでフェノームデータベースが構築されている.
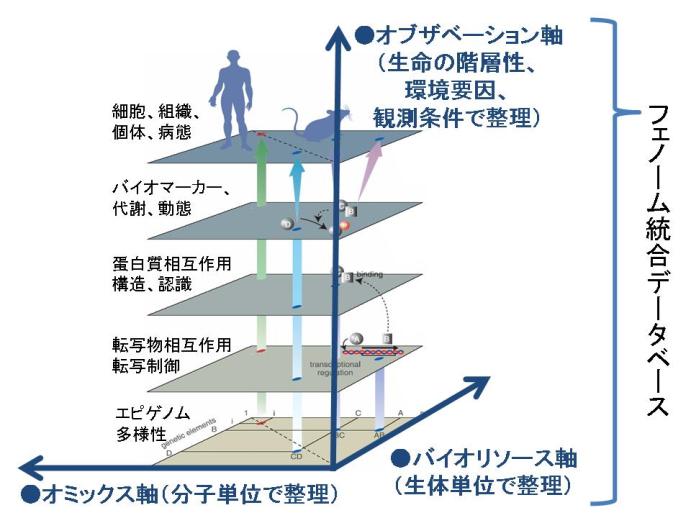
図1.オミックスによる生命システムの階層化
ここでは遺伝子A,B,C,Dが発現しており,転写制御,タンパク質相互作用など,縦横にはりめぐらされた立体的なネットワークがある.生命の理解には,ゲノムからフェノームまですべてを包含したネットワークの解明が不可欠である.
従来のデータベースの統合化における問題点
従来の生物学では,種の概念というおおまかなくくりのもと,遺伝型とフェノタイプ(表現型)との因果律(原因と結果との対応関係)を集積することで知識の統合化が試みられてきた.しかし実際には,同じ種であっても系統や株の細かな違いを無視あるいは見逃すことも多く,同一の条件で観測を行っても結果の異なる場合が多い(多様性の同一視による過誤).同じことは,観測条件の多様性にもあてはまる.たとえば,マウスについては2000年代よりフェノームデータベースの統合化が国際的に試みられており,同じ系統のマウスを同じように観察しても研究組織のあいだで矛盾するデータが得られるケースのあることが問題となっている.それは,マウスを飼育する箱の大きさや匹数が異なるなど,いっけん,ささいな環境の違いから生じることもある.このため,従来のように個別性の記載があいまいなまま統合化する方法では,生物材料とフェノタイプとの対応関係がくずれてしまうという問題が生じていた.
これから求められるデータベースの統合化
以上の理由から,フェノームデータベースを統合化する際には,個体と環境の多様性がフェノタイプに大きく影響することを十分に認識することが必要となる.理想的には,同一の品質の生物材料に対し同じ計測手段を統一的に適用したうえでデータを比較することが重要である.たとえば,国際マウス表現型解析コンソーシアム(International Mouse Phenotyping Consortium:IMPC)では米国NIHより予算の供給をうけ,2011年より,すべてのノックアウトマウスの系統に対する標準化された解析プラットフォームを用いた大規模な解析を国際的な連携により開始している[1].
また,ゲノム解析技術の発達によりおのおのの生物材料の個別性を明確に記述することが可能になっているため,ユーザの要求に答えるデータベースでは"生物材料"や"解析プラットフォーム"の個別性が記述の基本単位となっている.さらに一方では,計測条件を完全に同一とすることは困難なため,個別性を保持しながら類似性を基準に情報を統合することが必要であり,これを可能にするオントロジーが必要となっている.
多様性の階層的な統合化に用いるオントロジー
オントロジーとは物事を体系的に説明するためのある種のデータベースである.従来のデータベースのような表形式の整理にくわえて,ツリー状の階層的な分類といったしくみが導入されている.このツリー構造により個別性と類似性とを両立させることができる.このようなしくみにより,類似したプラットフォームにおける実験条件を同一視して比較したり,観測結果であるフェノタイプを測定対象の形質やその測定結果に応じて相互に比較したりすることができる.
さらに近年では,データベースやアプリケーションの壁をこえて世界中で情報を利用することを可能にするためのしくみが整いつつある.従来のデータベースにおける表形式は,人がみた場合には直観的にわかりやすくても,表の各列(項目)が何を示しているのかをデータベースのあいだで共有するための方法は備えていない.そのためたとえば,特定の項目が"マウス体重"を示していても,このことをデータベースのあいだで共有するためにはデータベースの構築者どうしが直接やりとりしなければならない.これを解決したのが,WWWコンソーシアムが世界標準として勧告しているRDF(resource description framework)というデータフォーマットである.RDFは,それぞれのデータを世界で唯一の識別子URI(uniform resource identifier)により管理し,これにもとづきそれぞれの項目が何であるかを記述することができるなど,データを相互にやりとりするためのデータ(メタデータ)を扱う枠組みを備えている.さらに,RDFにより構築される上位の記述言語OWL(web ontology language)を用いると,オントロジーのしくみを用いることで,たとえばデータベースAにおける"マウス体重"とデータベースBにおける"body weight"とが同じ項目であることや,"質量とは物の性質のひとつである"とか"10 gとは質量を示す定量値のひとつである"といった項目そのものの意味を示すこともできる.このようなしくみによりインターネット上の情報を知識化しようという構想は"セマンティックウェブ"とよばれている.同じく,このようなしくみのうえで自由に利用できるデータはリンクドオープンデータ(liked open data:LOD)とよばれ,インターネットを介した情報共有の新しいかたちとして期待されている.
以上のセマンティックウェブの技術面での詳細は,本シリーズ第2回「データベースを統合利用するための基盤としてのセマンティックウェブ技術」(URL:https://events.biosciencedbc.jp/article/02)を参照されたい.
フェノームデータベース統合化の実際
筆者らは,これまで述べたことの実践として,マウスやシロイヌナズナなど代表的なバイオリソースを出発点としてフェノーム統合データベースの構築を試みている.まず,"フェノタイプ"という概念の本質,すなわち,測定対象である1)生物体が,2)どういった性質をもつのか,という2つの自由度(パラメーター)が核となることに注目した.そのうえで,さらに必要なパラメーターとして,尺度水準(計測データを変数として扱うための数学的な分類で,定量値や定性値をさらに詳細に分類したもの),解剖学的な部位,生物学的なステージ(発生,成長,生活環など),環境条件,測定方法,測定者/施設などを追加した.これらのパラメーターはそれぞれオントロジーにより記載されるので,多様性を分類階層において吸収し類似度を計算することができる.このようにすることで,いっけん,途方もなく多様なフェノタイプの情報を単一のデータ形式で格納することができ,しかも,一貫した方法で計算処理することができる.
この方法はとくに近縁の種のあいだでフェノタイプの同等性を推論するのに役立つ.たとえば,マウスにおいて"筋肉"の"萎縮"が観察された場合,"マウス筋肉"を相同組織の"ヒト筋肉"に変換することによりamyotrophy(筋萎縮症)という疾患と関連づけることができる.このような類似性は,生命現象を中心とした基礎研究を医学をはじめとする応用研究へとつなげることに利用できるので,コンピュータを用いて大量に提示することが有益である.一方,マウスとシロイヌナズナといった遠縁の種のあいだでは器官や組織の相同性の情報はほとんどなく,統合はむだと思われるかもしれない.しかし,それぞれの計測結果と同時に測定方法の情報を収集することで,異分野のあいだでの計測技術の移行を助けることになるものと考えられる.また,いかなる生物種のフェノタイプも記載が可能なデータベースを実装し継続的に運用することは,データの蓄積により生物のあいだの多様性の溝を埋め,遠縁の生物のあいだの関連性を推論するためのデータソースの実現のためにきわめて重要である.現在,筆者らは,それぞれのバイオリソースの基本情報およびフェノームデータの整備を進めている(図2).
おわりに
フェノタイプは遺伝学の黎明期に生まれた概念である.しかしながら,生命のすべての階層において観測される現象を記述しうる許容力をもつ.個々の生物のフェノタイプはほかの生物のフェノタイプと進化的また種間の相互作用などの関連性をもち,これらをすべて包括した概念がフェノームであるといえるだろう.フェノームには,研究分野や計測技術により分断された個々の現象の解釈ではなく,その壁をこえて,相互の共通点や相違点をさまざまな観点から解析し新たな仮説を生み出しその検証を導く,といった大きな可能性がある.近年のゲノム研究の進展により,分子パスウェイあるいは分子機構のデータの整備および統合が意欲的に進められている.フェノームは将来において統合すべきものとして取り残されてきた感があるが,近年では,オントロジーをはじめ統合のためのさまざまな基盤技術が整いつつある.筆者らは,生命科学データベースのパズルにおける最後の1ピースをはめ込み,さらにそのさきにある生命の包括的な理解にむけ進んでいきたいと考えている.
参考文献
- Abbott, A.: Mouse project to find each gene's role. Nature, 465-410 (2010) ↑
↑ 押下で本文に戻ります。

Licensed under a Creative Commons 表示2.1日本 license ©2012 豊田哲郎(理化学研究所生命情報基盤研究部門)、桝屋啓志(理化学研究所バイオリソースセンター マウス表現型知識化研究開発ユニット)
なお、本記事は細胞工学2012年2月号掲載の原稿を改変したものです。
